![]()
灵感来源
通过一个爬虫项目自动采集小说数据,通过后端统一提供服务接口,再用一个前端项目做阅读和运营界面,形成一条完整的小说内容链路。
项目简介
本系统是一个完整的 在线小说网站解决方案,由三个彼此解耦又紧密协作的子项目组成:
-
前端站点:ad-fiction-front
- 技术栈:Vue3 + Vite + Element Plus + Pinia + Axios。
- 负责:小说首页、详情、阅读、分类、排行、搜索、书架、评论、登录/个人中心等可视化页面。
-
后端服务:fiction
- 技术栈:Spring Boot 2.7.11 + MyBatis-Plus + MySQL + Redis + Sa-Token + Druid + x-file-storage + WebDAV。
- 负责:对外 REST API、业务逻辑处理、登录与权限、缓存、文件存储对接。
-
爬虫采集:fiction_spider
- 技术栈:Scrapy + PyMySQL + webdav4 + requests。
- 负责:从第三方小说站(如奇书网)批量采集小说及章节内容,写入 MySQL,并可将 txt/封面同步到 WebDAV。
整体形成:数据采集 → 数据存储 → 服务接口 → 前端展示 的闭环,既能快速搭建自己的小说站点,也可以作为一套学习/演示级的「全栈 + 爬虫」综合项目。
核心亮点
- 端到端闭环:从爬虫采集到前端阅读,覆盖采集、存储、缓存、鉴权、文件服务、展示全链路。
- 技术栈常用、易扩展:后端基于 Spring Boot + MyBatis-Plus,前端基于 Vue3 + Vite,爬虫基于 Scrapy,学习和维护成本低。
- 文件与数据分离:章节内容/封面等大文件可以通过 WebDAV 独立存储,MySQL 仅承担结构化数据,利于扩展与迁移。
- 认证与书架/评论体系:引入 Sa-Token 与 Redis,实现登录态管理、书架、评论等基础社区能力。
总体架构图
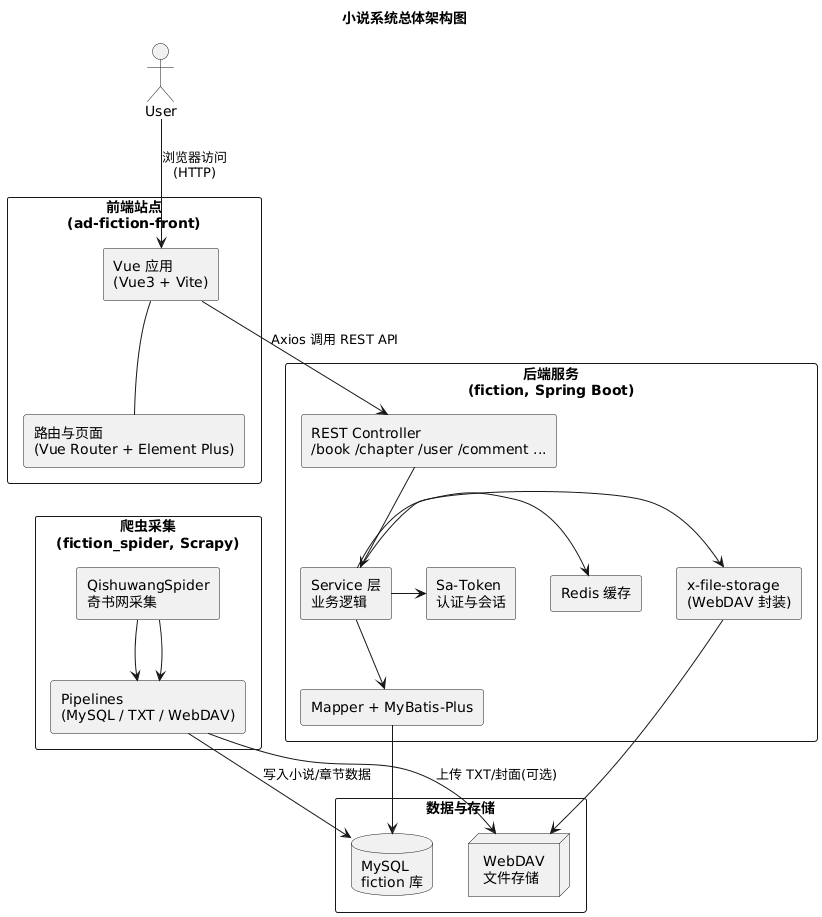
项目地址
GitHub 仓库: https://github.com/2585570153/ad-fiction-front https://github.com/2585570153/fiction https://github.com/2585570153/fiction_spider
Gitee 仓库: https://gitee.com/tian3615/ad-fiction-front https://gitee.com/tian3615/fiction https://gitee.com/tian3615/fiction_spider
数据源
项目中所涉及的图片和文本内容已经打包成zip包 可供下载
https://www.123865.com/s/Z7EcVv-QaStd
项目开发阶段采用123云盘的webdev方式上传,并且通过直链鉴权方式提供阅览,后续可自行开发其他存储方式
开发接口说明
https://docs.apipost.net/docs/2d7a593fb864000?locale=zh-cn
项目预览图
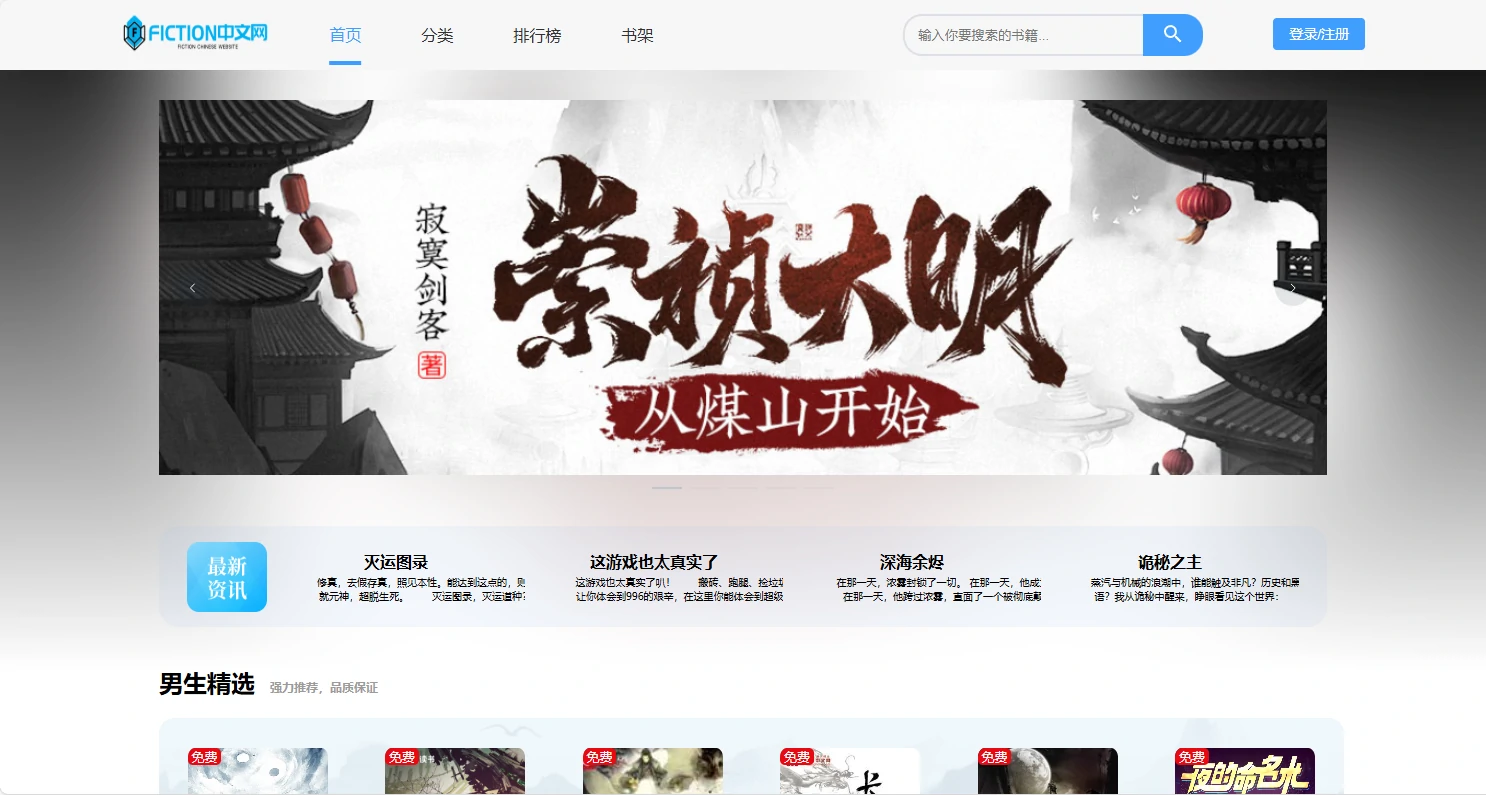
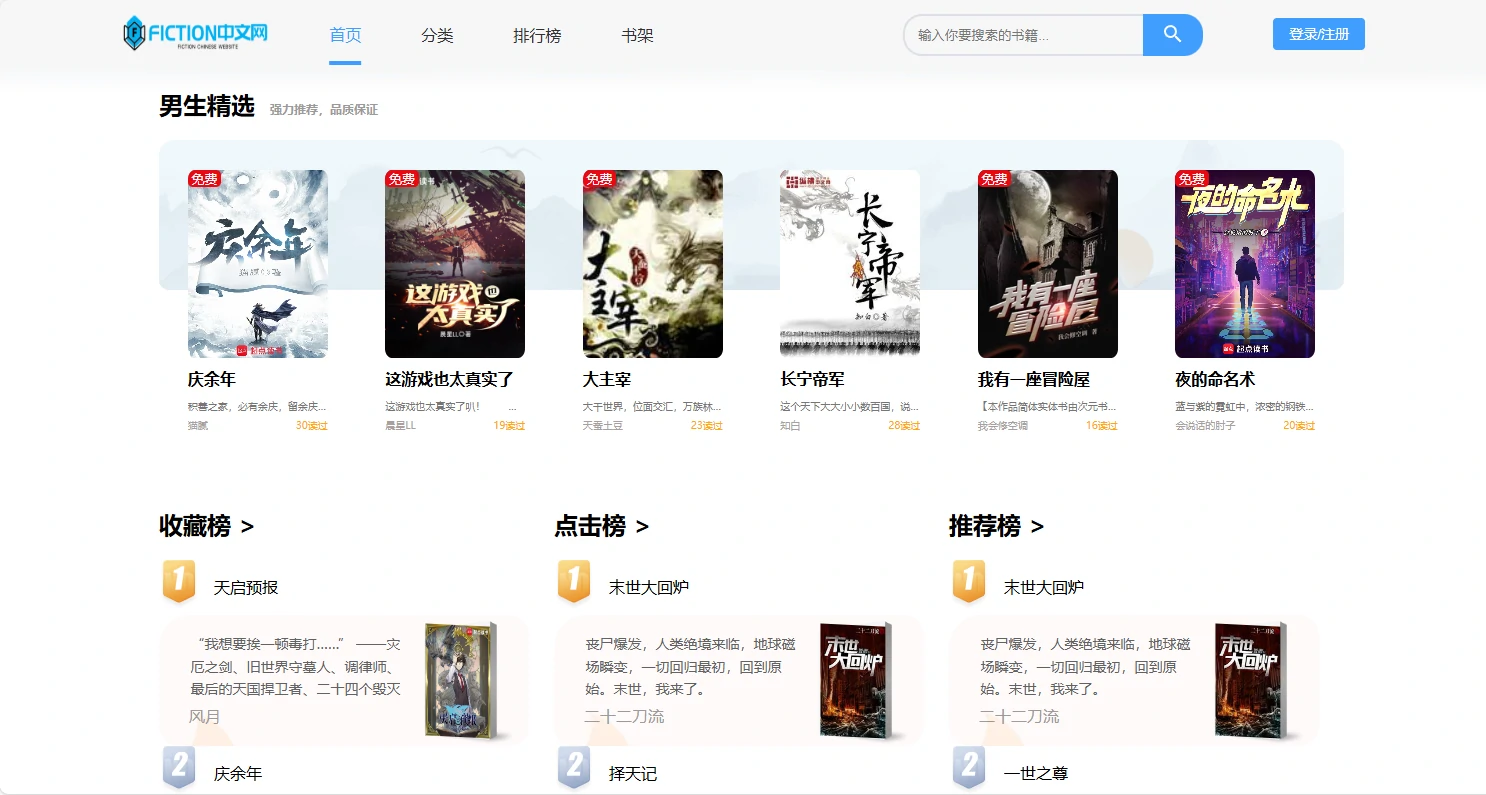
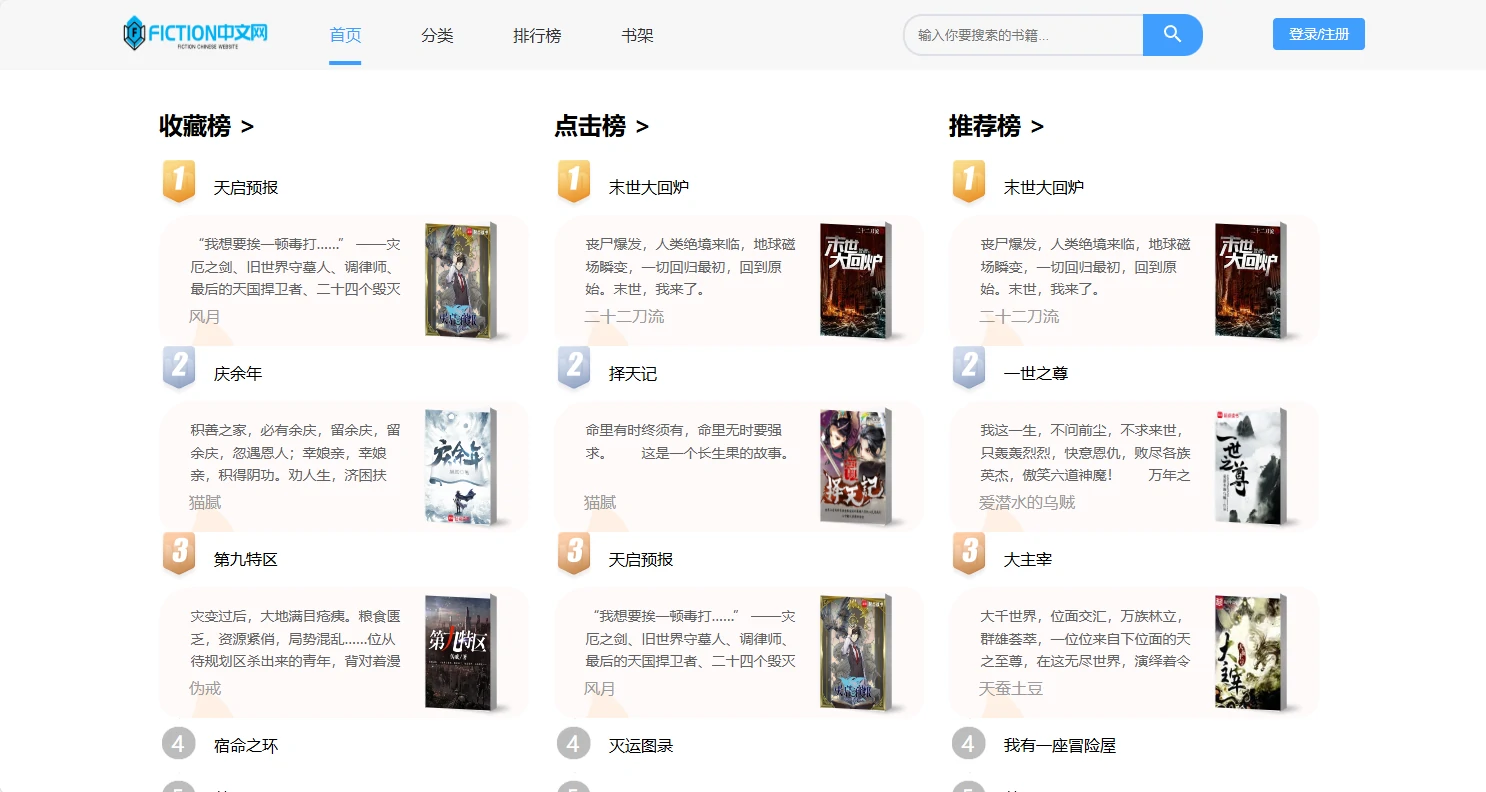
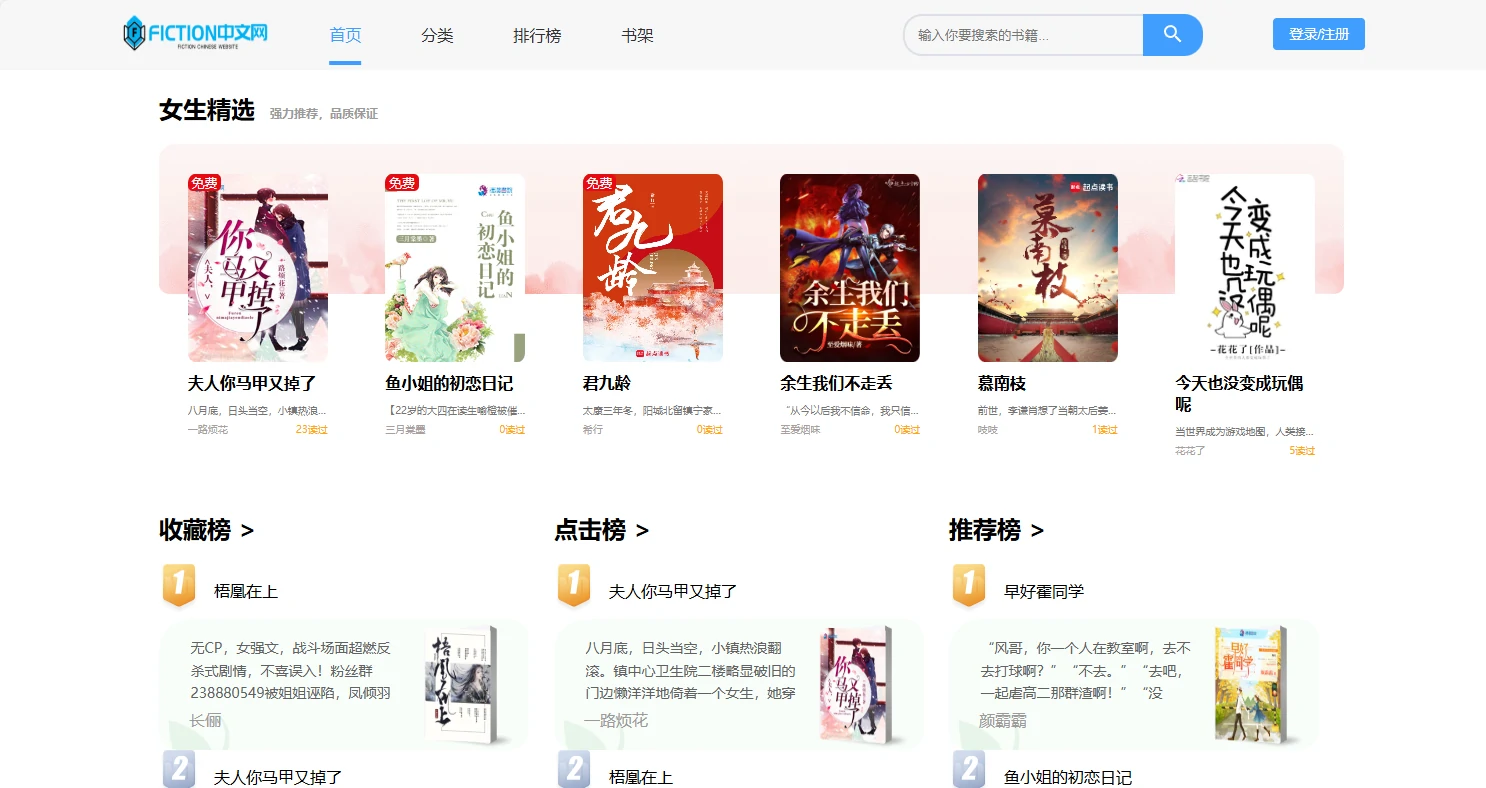
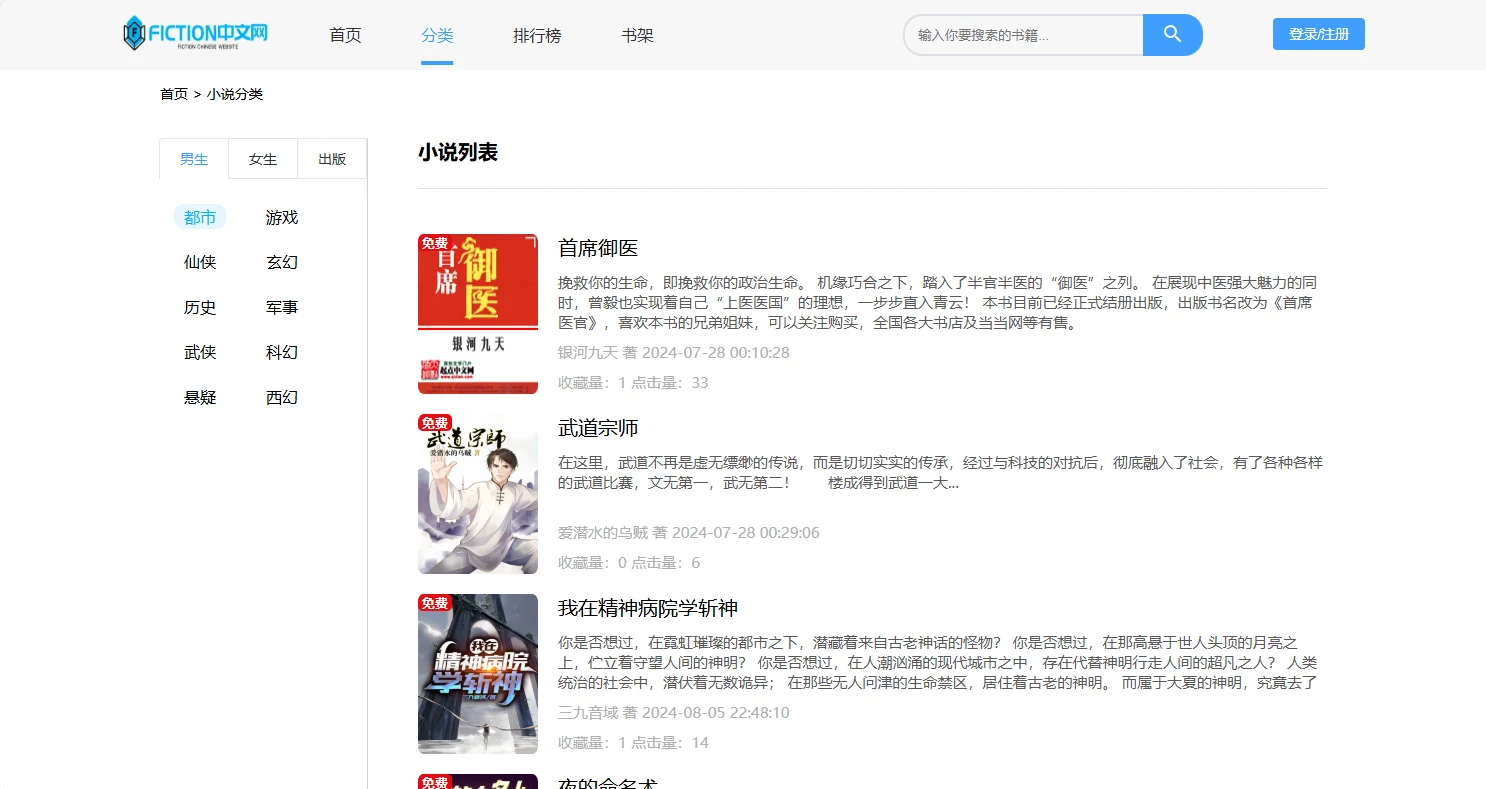
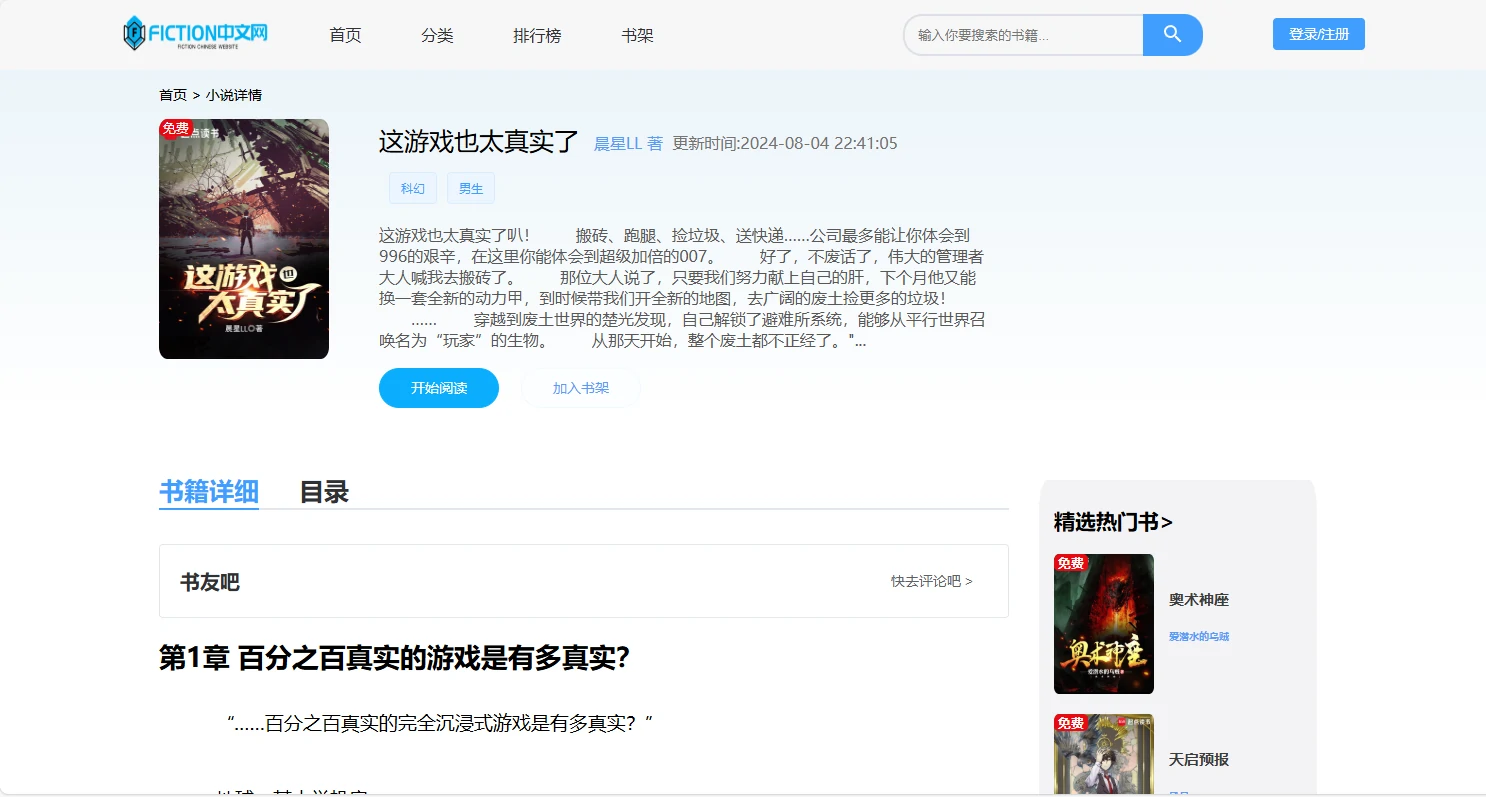
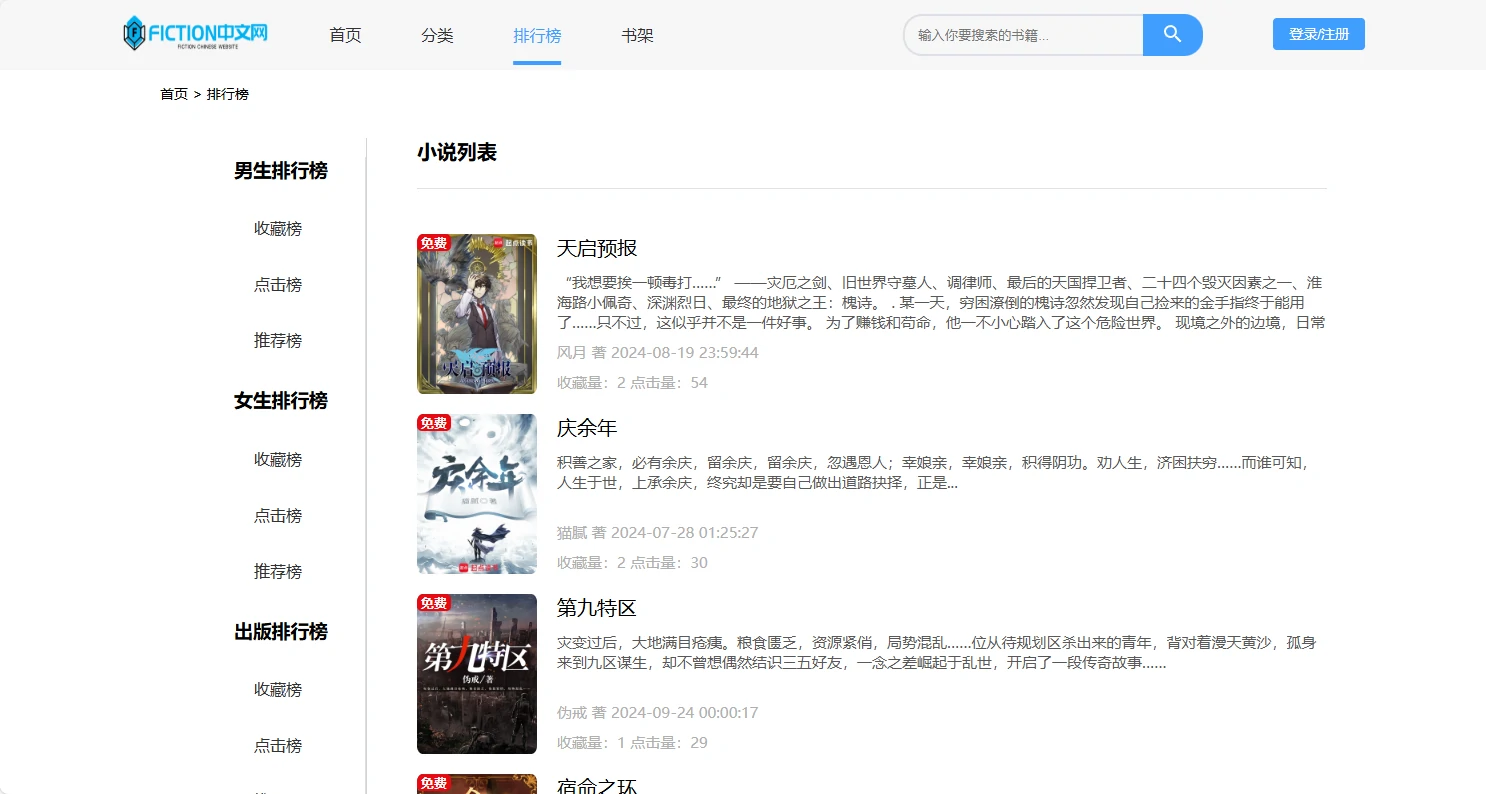
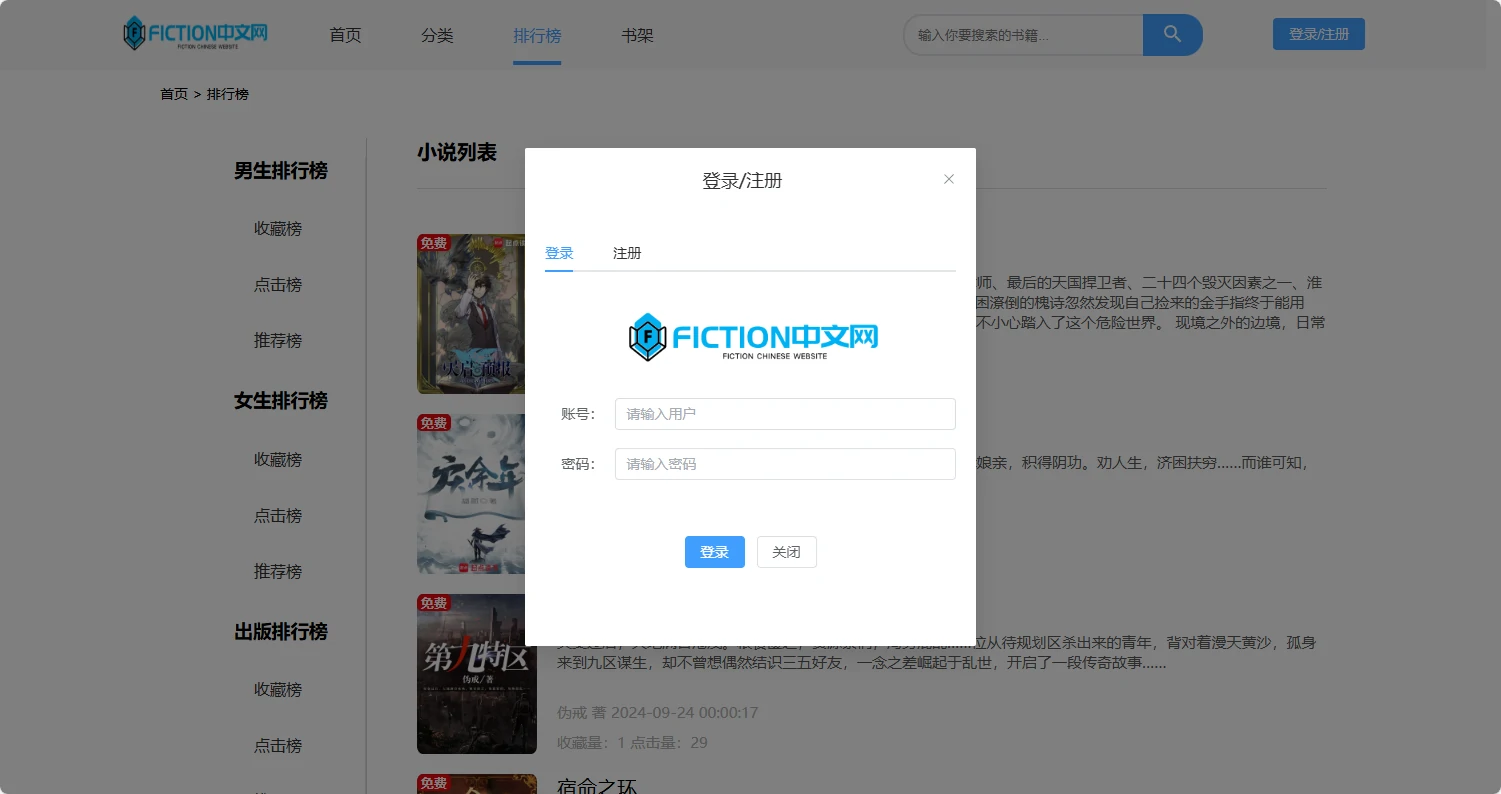
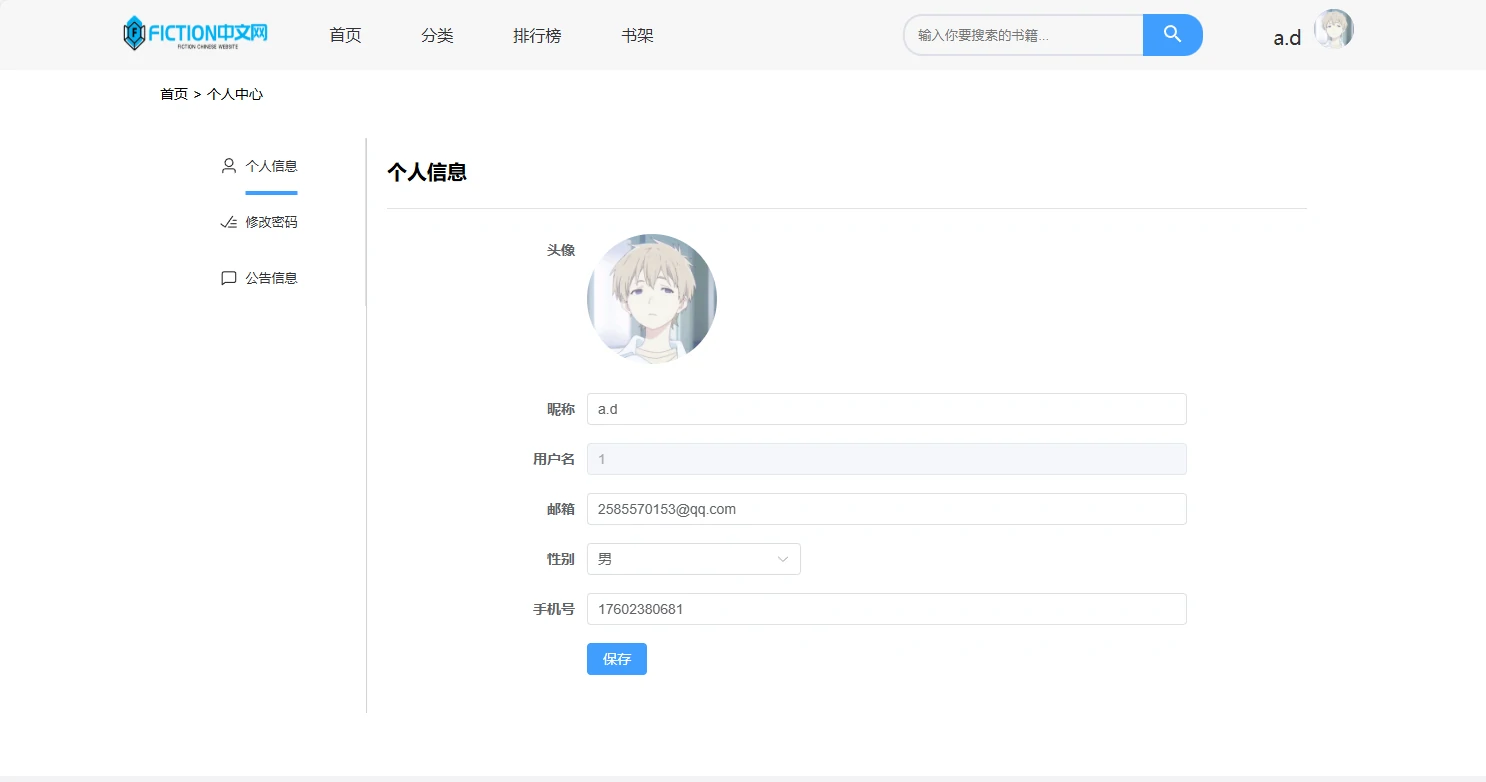
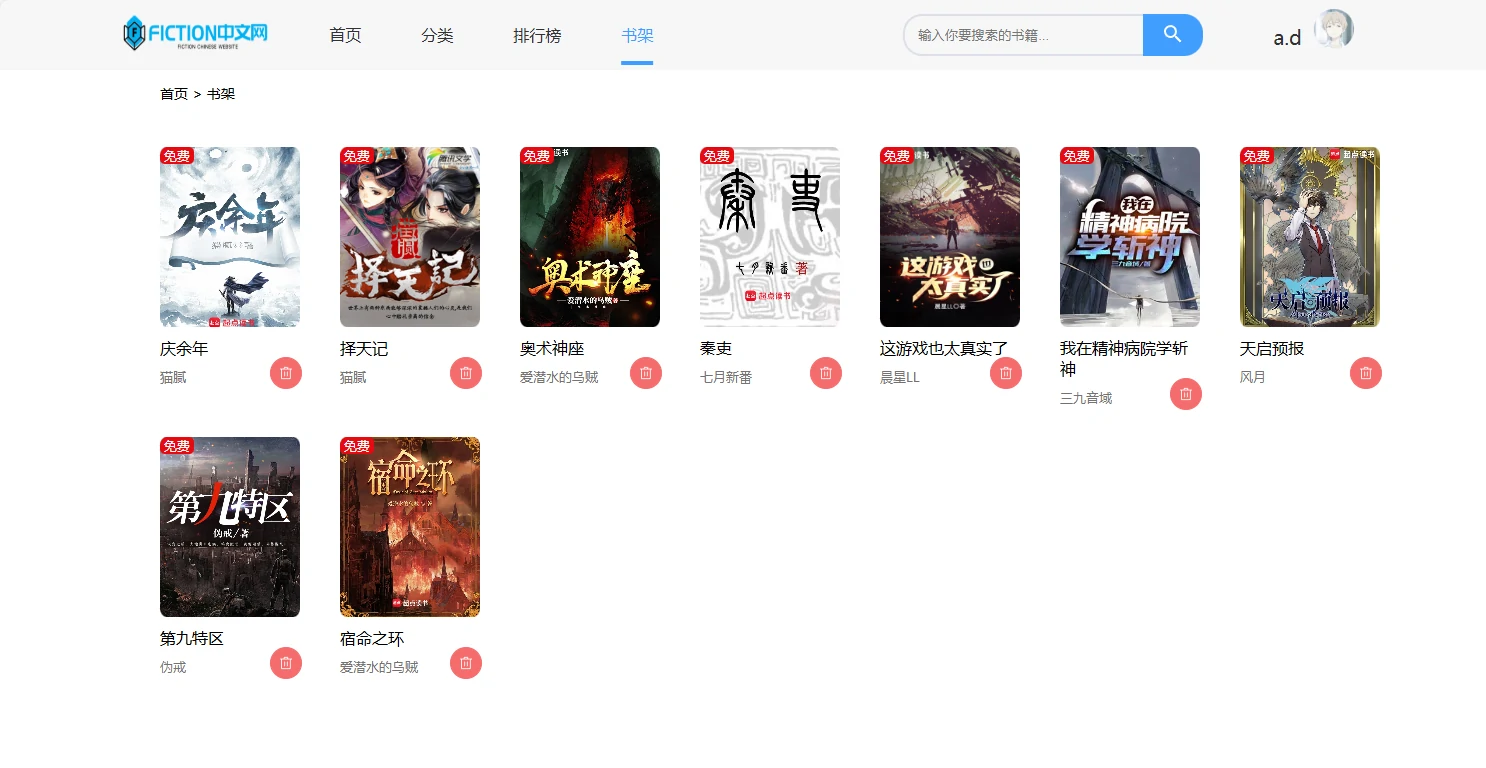

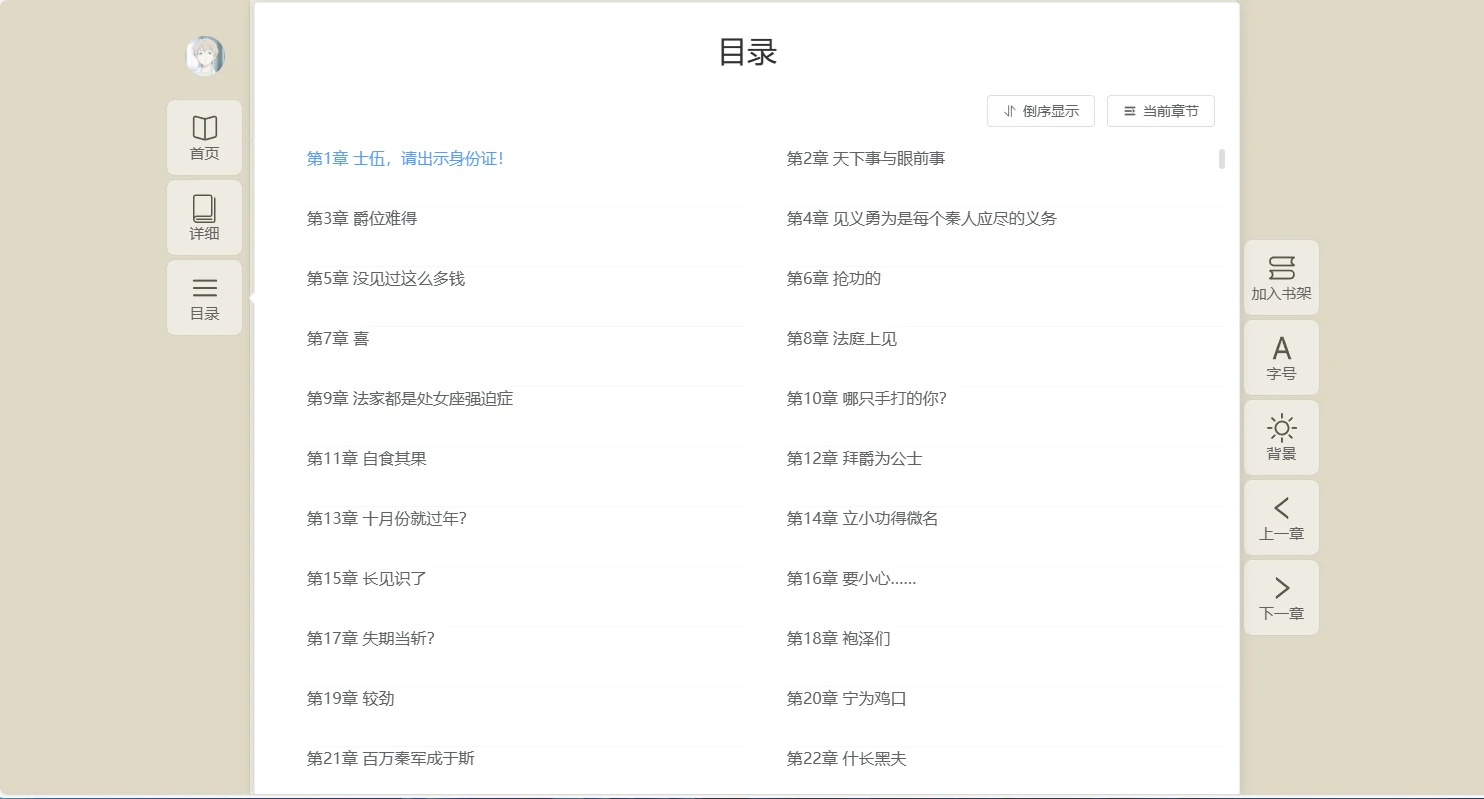
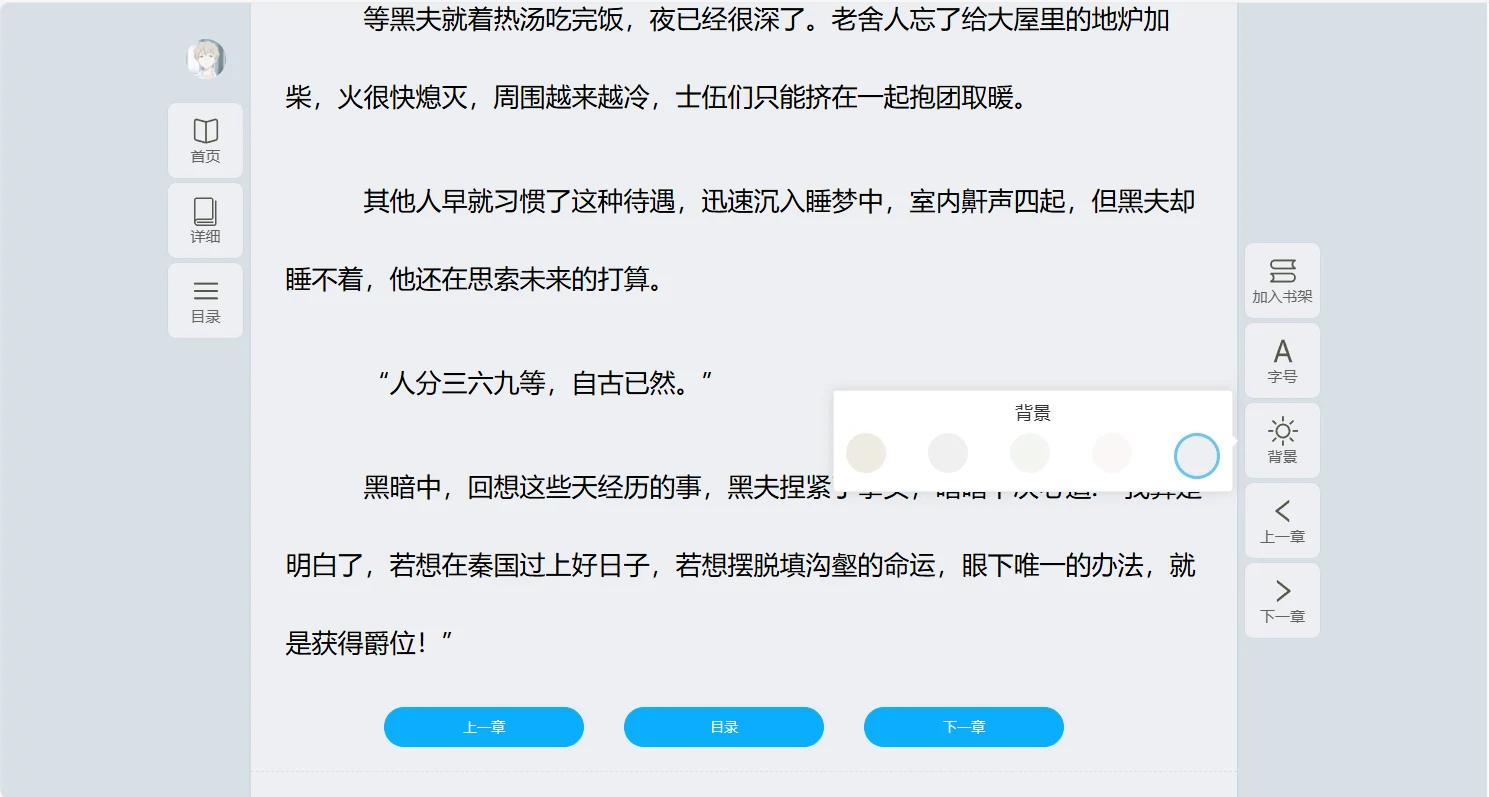
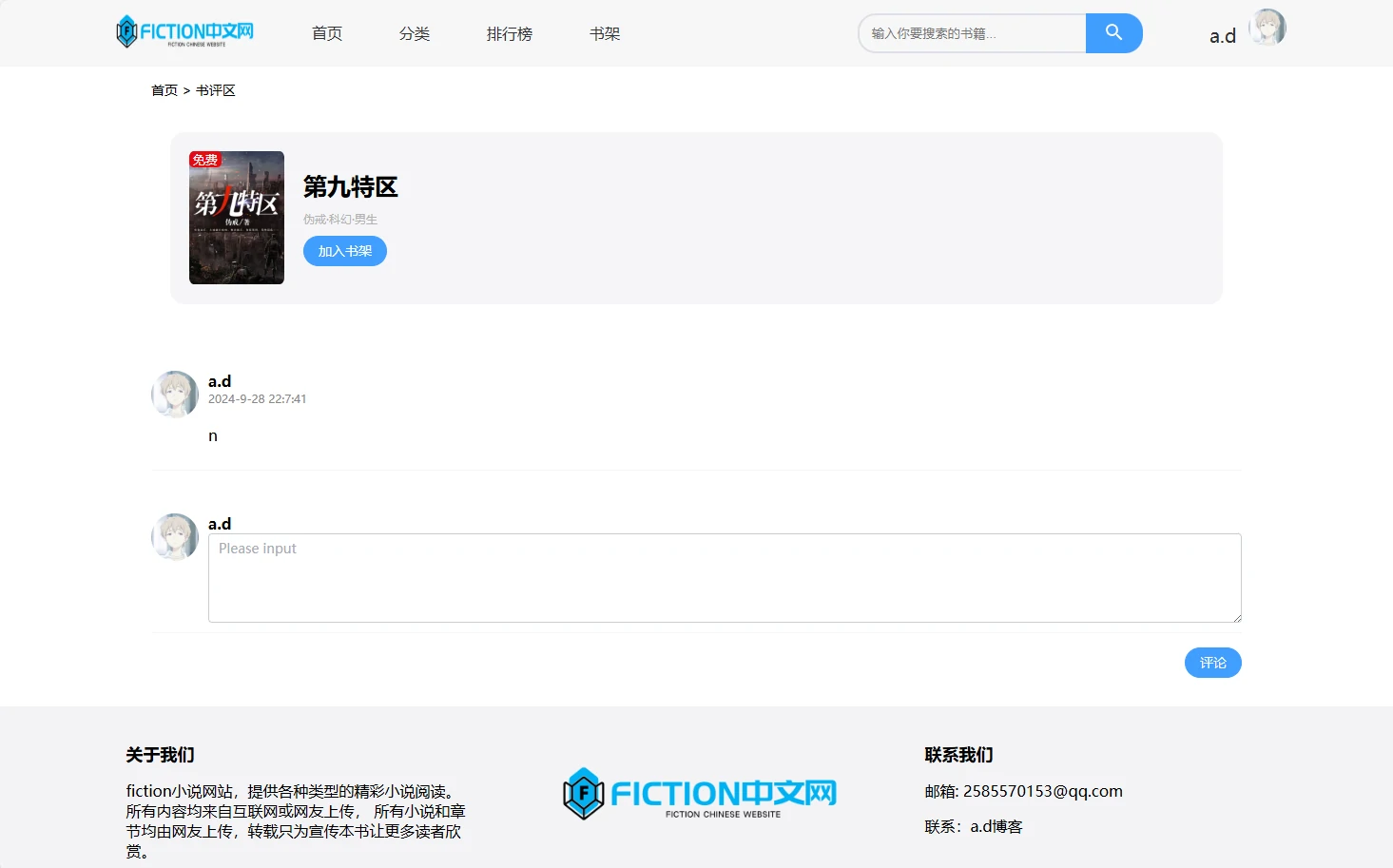
系列开发笔记
fiction中文网flutter代码分析 | ad博客 该子项目开发失败 已放弃
各子系统详细说明
1. 前端ad-fiction-front
1.1 技术栈与特点
- Vue3 组合式 API,组件更加清晰易复用。
- Vite 开发服务器,热更新快、构建效率高。
- Vue Router 4 管理前端路由与页面跳转。
- Pinia +pinia-plugin-persistedstate 管理登录状态、阅读进度等需要持久化的数据。
- Element Plus 提供成熟的 UI 组件体系(表单、对话框、表格、布局等)。
- Axios 封装 HTTP 请求,统一处理后端响应和错误。
1.2 页面路由与主要业务
核心路由(来自src/router/index.js):
-/:首页布局Layout,可承载推荐、轮播、各类榜单等模块。
-/detail/:id:小说详情页,展示简介、作者、分类、最新章节等信息。
-/read/:tableName/:fictionId/:id:阅读页,从后端加载指定章节内容。
-/category/:bigclass/:id/:classify?:分类页,支持按大类/小类筛选。
-/rankinglist/:bigclass/:id/:rankinglist:多维度排行榜(点击、收藏等)。
-/bookrank:书架页,管理用户已收藏的小说。
-/search/:name/:id:搜索结果展示。
-/login:登录页,与后端 Sa-Token 对接。
-/info:个人信息与账号设置。
-/comment/:id:评论页,围绕指定小说展开评论。
-/mobile:移动端专用布局。
-/test:测试/调试用页面。
路由守卫中根据 UserAgent 判断是否为移动端,将to.meta.isMobile 设置为true/false,为响应式布局和差异化页面提供依据。
1.3 与后端接口对接
- 所有接口封装在src/apis 目录下,如:
-bannerAPI.js:首页 banner / 推荐位。
-fictionAPI.js:小说列表 & 详情。
-chapterAPI.js:章节内容相关接口。
-commentAPI.js:评论增删查接口。
-rankinglistAPI.js:排行榜查询接口。
-searchAPI.js:搜索接口。
-userAPI.js:登录 / 用户信息接口等。 - Axios 实例统一在utils/http.js 中创建,Base URL 一般指向http://localhost:8080 或你的后端域名。
2. 后端fiction
2.1 技术架构
- Spring Boot 2.7.11:作为应用基础框架,统一管理依赖与启动流程。
- MyBatis-Plus:在 MyBatis 基础上提供自动 CRUD、分页、Wrapper 等能力。
- MySQL:保存核心业务数据(小说、章节、用户、书架、评论、公告等)。
- Redis:缓存热点数据、存储会话信息,加速访问并减轻数据库压力。
- Sa-Token:完成登录态与权限控制,支持多端登录、Token 策略配置。
- Druid:稳定的数据库连接池,支持监控与性能优化。
- x-file-storage + WebDAV:提供统一的文件存储抽象,将封面、章节文件等资源存放至 WebDAV,便于横向扩展和迁移。
2.2 模块说明
-controller:REST 接口层,对应小说、章节、用户、评论、书架、排行等模块。
-Service:业务服务层,封装所有业务逻辑与事务控制。
-mapper:持久层接口,使用 MyBatis-Plus 与数据库交互。
-entity:实体类,映射 MySQL 表结构。
-common:通用返回结果R、全局异常处理器等。
-config:MyBatisPlusConfig、RedisConfig、ServletConfig、Sa-Token、文件存储配置等。
-filter:Sa-Token 过滤器、安全拦截相关配置。
-utils:工具类(时间、JSON、分页、文件等)。
3. 爬虫fiction_spider
3.1 功能定位
- 针对第三方小说站(如奇书网)进行定向采集。
- 根据用户输入的小说目录页 URL,批量抓取小说基础信息与全量章节内容。
- 将解析出的结构化数据写入 MySQL,并可通过 pipelines 输出 txt 文件和上传 WebDAV。
3.2 Scrapy 项目结构
-spiders/qishuwang.py:奇书网主爬虫,实现start_requests /parse /contenturl 三个核心流程。
-items.py:定义FictionItem,包含小说名、作者、封面、简介、章节标题、章节内容等字段。
-pipelines/pipelines.py:负责使用 PyMySQL 将 Item 写入 MySQL。
-pipelines/txt_pipelines.py:负责生成 txt 并调用 WebDAV 上传(视实际实现而定)。
-utils/WebDAVUploader.py:WebDAV 上传工具类。
-settings.py:Scrapy 全局配置(并发、UA、日志级别、MySQL 连接等)。
使用流程
-
准备基础环境
- 安装并启动 MySQL,创建数据库fiction。
- 安装并启动 Redis。
- 准备 WebDAV 服务(可以是云盘 WebDAV 或自建服务),记录好地址、用户名、密码。
-
运行爬虫初始化数据(推荐)
-
在fiction_spider/fiction/settings.py 中配置 MySQL 和 WebDAV。
-
执行: bash cd fiction_spider scrapy crawl qishuwang
-
按提示输入目标小说目录页 URL,等待采集完成,确认 MySQL 中已有小说及章节数据。
-
-
启动后端fiction
-
修改fiction/src/main/resources/application.yml: -spring.datasource.druid:MySQL 地址、用户名、密码。
-spring.redis:Redis 地址、密码。
-dromara.x-file-storage.webdav:WebDAV 地址、账号、密码等。 -
启动: bash cd fiction mvn spring-boot:run
-
使用 Postman 或浏览器调用部分接口,确认后端工作正常。
-
-
启动前端ad-fiction-front
-
在前端项目中将 Axios Base URL 指向后端地址,如http://localhost:8080。
-
启动: bash cd ad-fiction-front npm install npm run dev
-
打开 Vite 提示的地址(一般http://localhost:5173),体验完整的小说阅读流程。
-