灵感来源
在构建智能问答系统时,需要处理多种格式的文档、支持向量检索、集成工具能力,并提供一个完整的RAG(检索增强生成)解决方案。本项目整合了文档处理、向量存储、工具插件等核心功能,打造了一个功能完善的多模态智能问答平台。
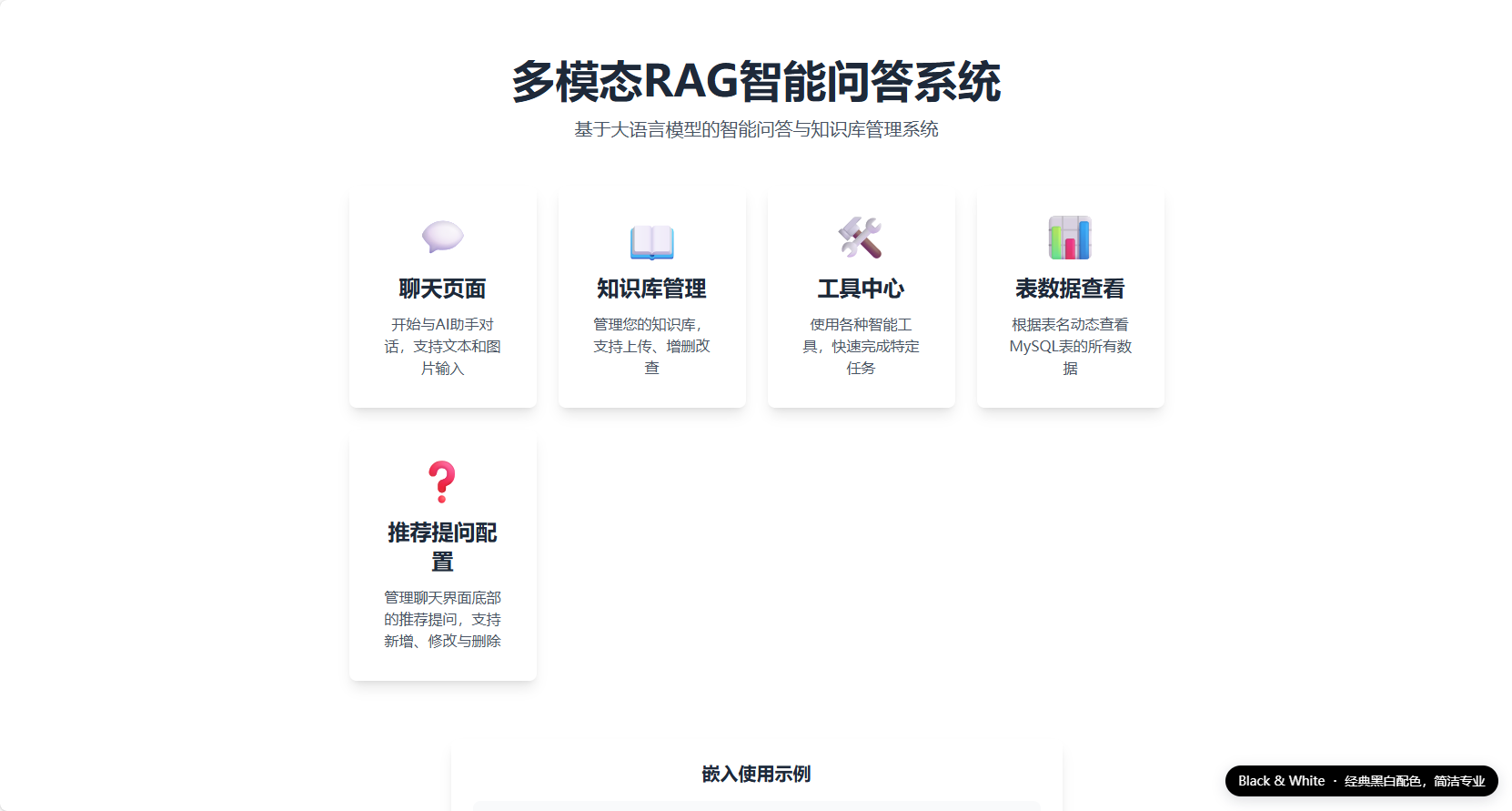
项目简介
多模态RAG智能问答系统是一个基于FastAPI构建的智能问答平台,集成了文档处理、向量检索、工具插件等核心能力。系统支持PDF、Word、Excel、图片等多种格式的文档上传,通过ChromaDB进行向量存储和语义检索,结合大语言模型实现智能问答。同时提供了插件化的工具系统,支持自定义工具扩展,满足不同业务场景的需求。
项目地址
- 演示地址: 主页右下角聊天界面 https://www.aiheadn.cn/
- GitHub 仓库: https://github.com/2585570153/langchainModule
- Gitee 仓库: https://gitee.com/tian3615/langchain-module
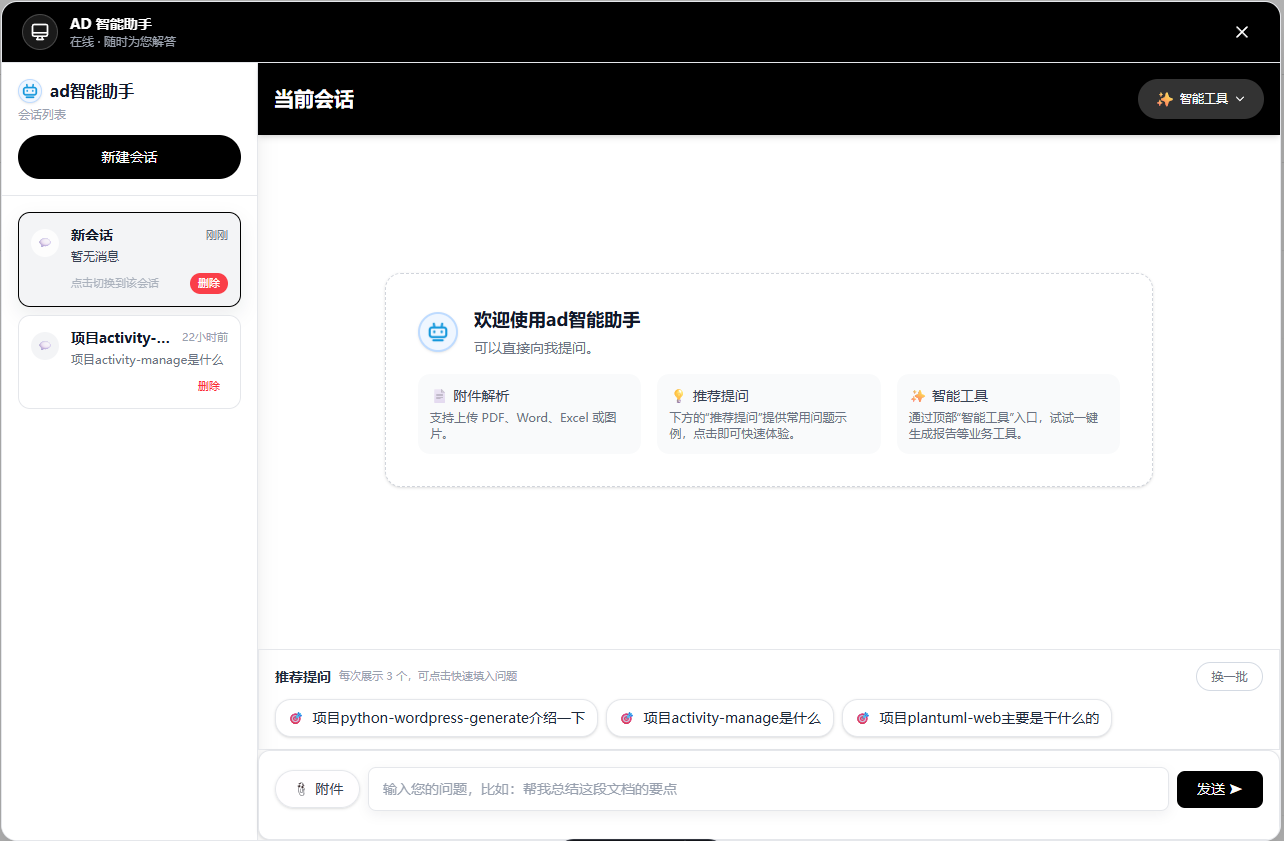
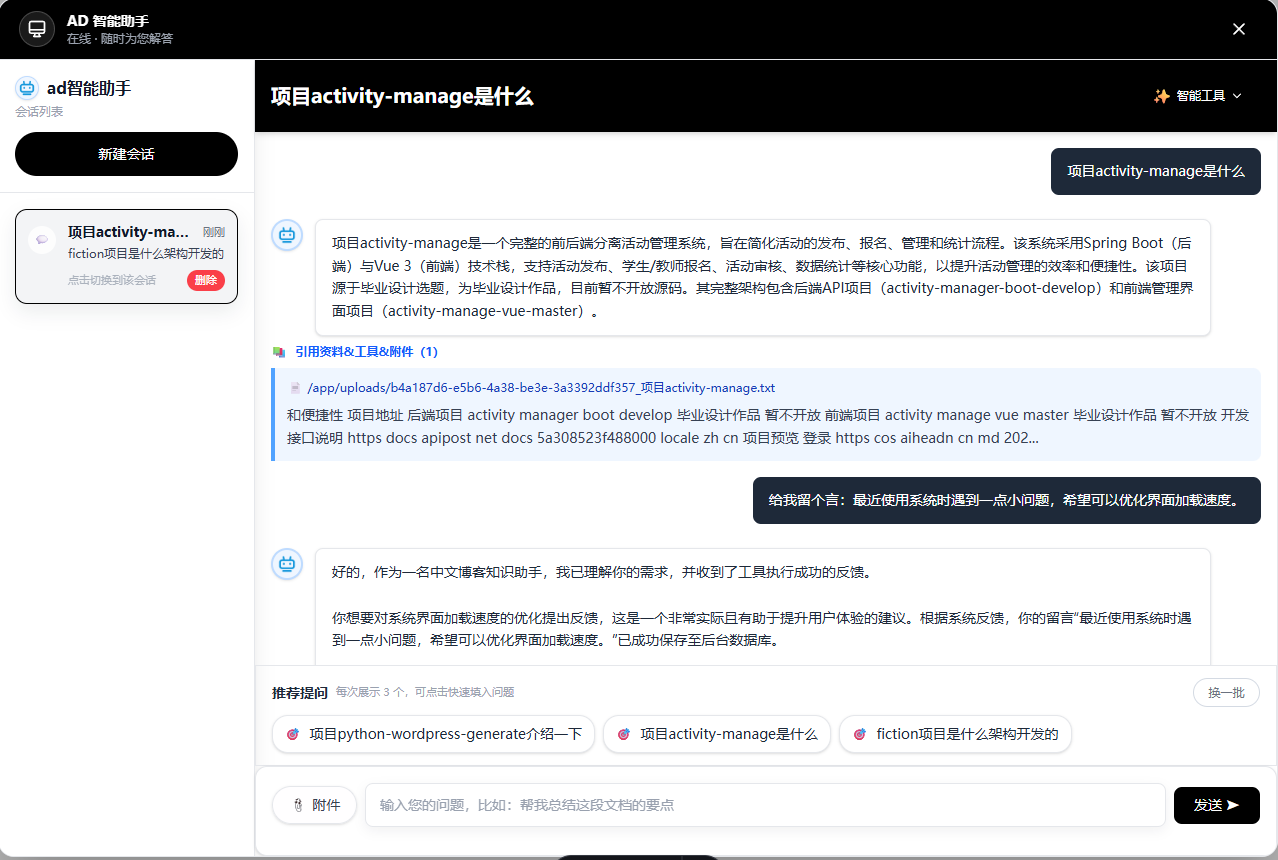
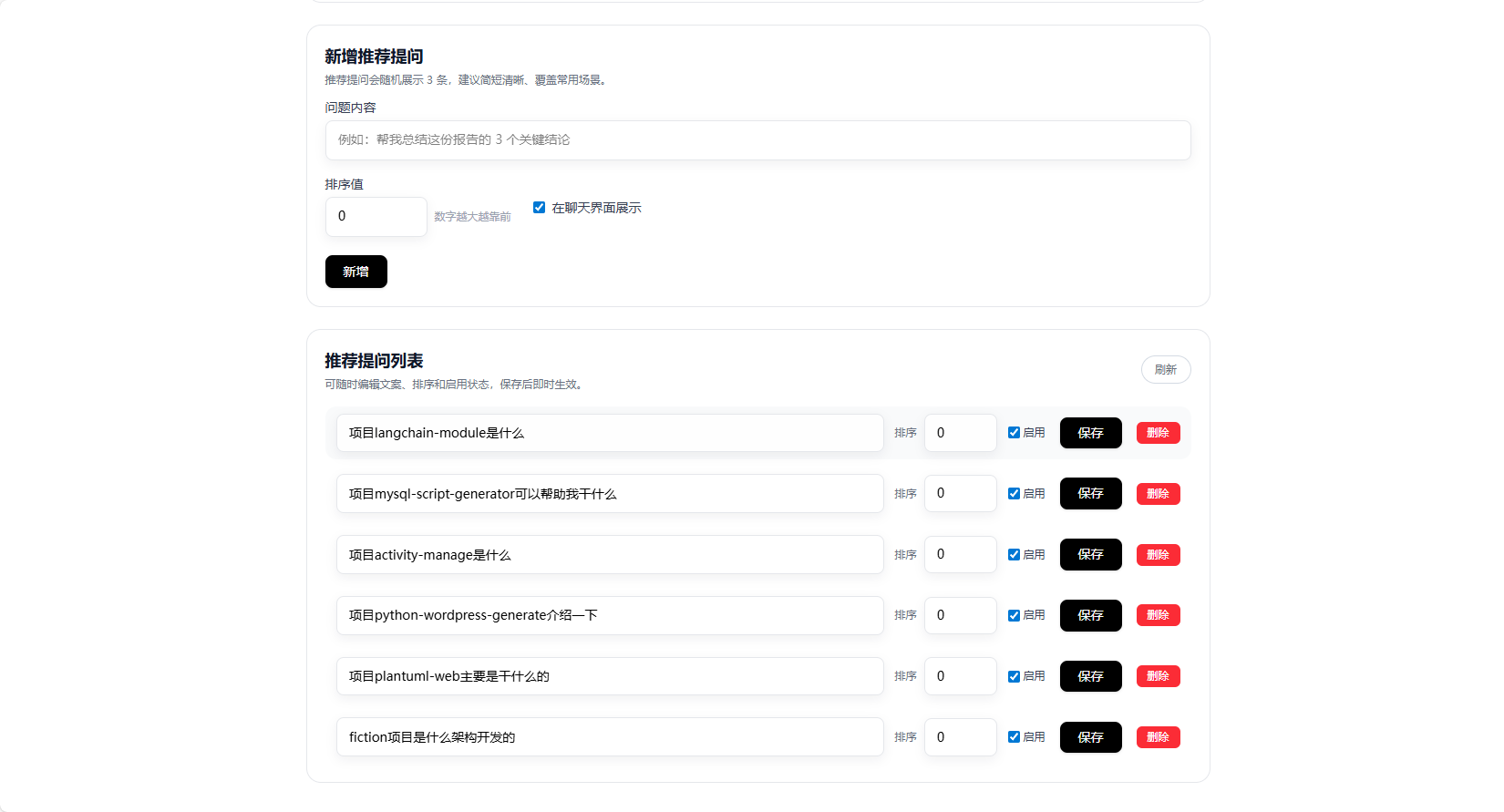
项目预览
技术栈
| 类型 | 框架/库 | 说明 |
|---|---|---|
| 后端框架 | FastAPI | 高性能异步Web框架 |
| 数据库 | MySQL | 关系型数据库,存储会话、知识库等元数据 |
| 向量数据库 | ChromaDB | 持久化向量存储,支持语义检索 |
| ORM | SQLAlchemy | Python ORM框架 |
| AI模型 | 千帆平台 | 兼容OpenAI API格式的聊天和向量模型 |
| 前端 | HTML/CSS/JavaScript | 原生前端技术 |
| 前端样式 | Tailwind CSS | 现代化CSS框架 |
| 文档处理 | pypdf, python-docx, pandas | 支持PDF、Word、Excel等格式 |
| OCR | rapidocr-onnxruntime | 图片文字识别 |
项目亮点
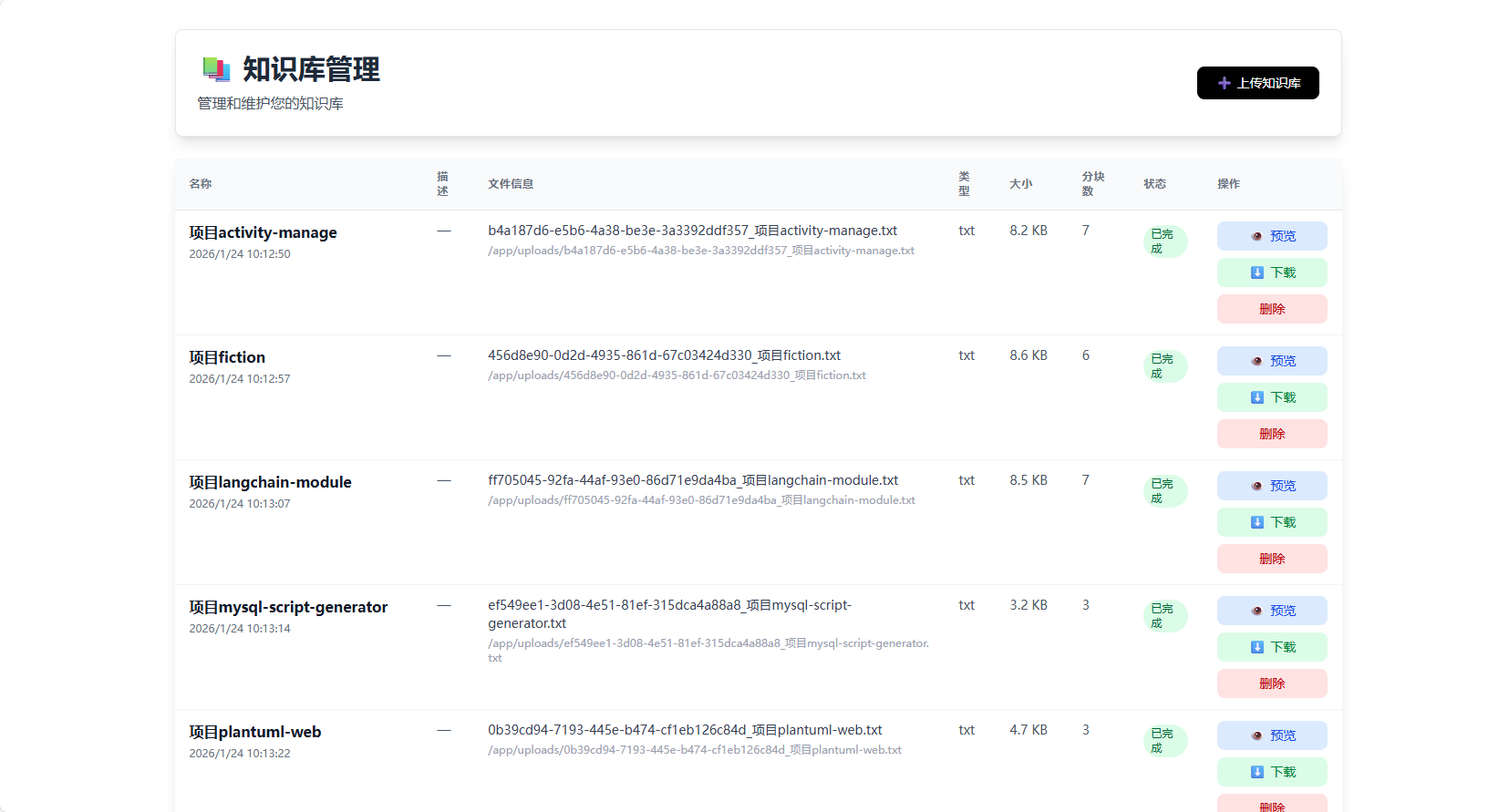
支持PDF、Word、Excel、TXT、图片等多种格式的文档上传和处理。系统自动识别文档类型,提取文本内容,对于图片文件还支持OCR文字识别,实现真正的多模态文档处理能力。
基于ChromaDB向量数据库实现语义检索,支持文档分块、向量化存储和相似度检索。在回答用户问题时,系统会从知识库中检索相关文档片段,作为上下文提供给大语言模型,显著提升回答的准确性和相关性。
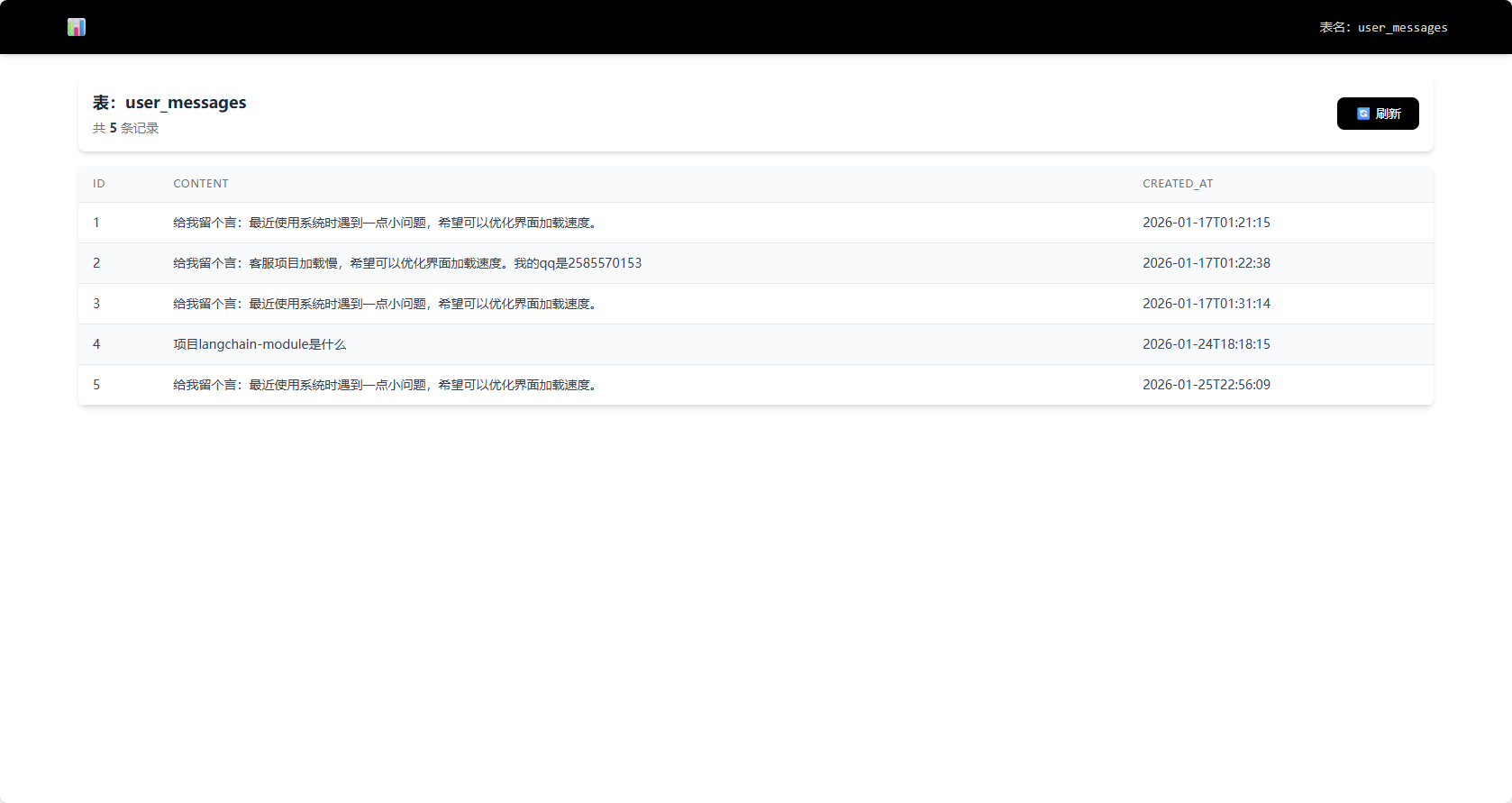
完整的会话管理系统,支持多用户、多会话的隔离。所有数据存储在本地数据库和向量库中,支持Token使用量追踪,确保数据安全和资源可控。
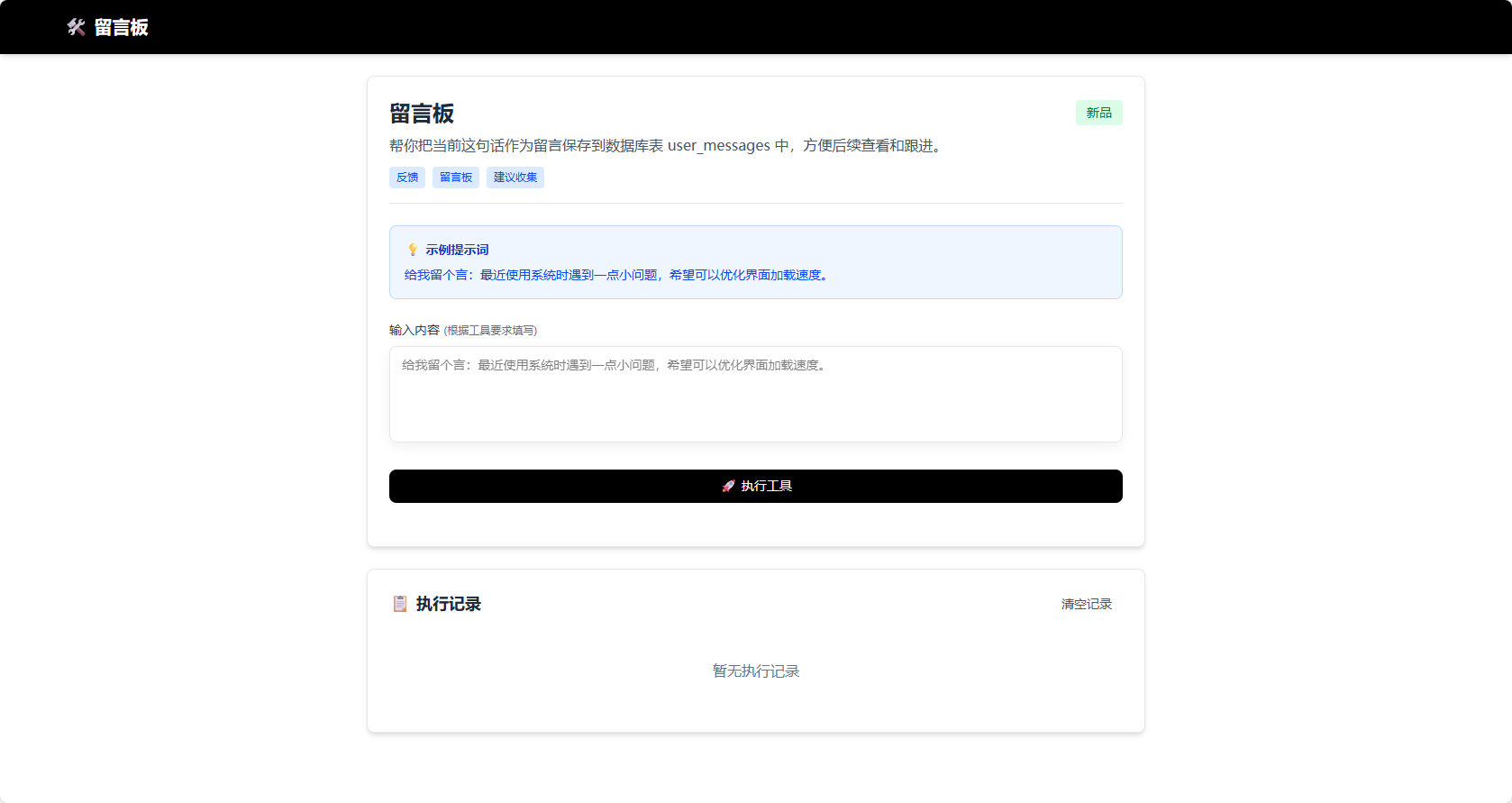
采用插件化架构设计工具系统,支持自定义工具扩展。工具通过统一的接口注册和执行,支持关键词触发、优先级配置等功能。系统内置了信息登记、PDF报告生成等示例工具,开发者可以轻松扩展新工具。
支持配置推荐问题列表,帮助用户快速了解系统能力,提升交互体验。推荐问题支持分类、标签、优先级等配置,可根据业务场景灵活调整。
使用流程
1. 环境准备
# 克隆项目
git clone [项目地址]
# 进入项目目录
cd langchainModule
# 创建虚拟环境(可选)
python -m venv venv
venv\Scripts\activate # Windows
# source venv/bin/activate # Linux/Mac
# 安装依赖
pip install -r requirements.txt
2. 配置设置
编辑 config.py 文件,配置以下信息:
- MySQL数据库配置:数据库地址、端口、用户名、密码、数据库名
- 应用配置:服务地址、端口、上传目录等
- AI模型配置:API密钥、模型名称、向量模型等
- ChromaDB配置:向量库存储路径、集合前缀等
3. 数据库初始化
系统启动时会自动初始化数据库表结构,确保MySQL数据库已创建并配置正确。
4. 启动服务
# 使用start.py
python start.py
5. 访问系统
- 主页面: http://127.0.0.1:8000/
- 聊天页面: http://127.0.0.1:8000/chat
- 知识库管理: http://127.0.0.1:8000/knowledge-base
- 工具中心: http://127.0.0.1:8000/tool
- 推荐问题配置: http://127.0.0.1:8000/recommend-questions
6. 使用知识库
- 进入知识库管理页面
- 创建新的知识库
- 上传文档(支持PDF、Word、Excel、TXT、图片等)
- 系统自动处理文档,生成向量索引
- 在聊天页面提问,系统会自动从知识库检索相关信息
7. 使用工具
- 进入工具中心页面
- 查看可用工具列表
- 配置工具参数(如需要)
- 在聊天中选择工具或使用关键词触发
- 系统执行工具并返回结果
功能特性
- ✅ PDF文档解析(逐页提取)
- ✅ Word文档解析(.docx格式)
- ✅ Excel文档解析(.xlsx, .xls格式)
- ✅ 纯文本文件解析(.txt格式)
- ✅ 图片OCR识别(支持中英文)
- ✅ 文档自动分块(可配置大小和重叠)
- ✅ 文档内容清洗和格式化
- ✅ 语义向量检索
- ✅ 相似度阈值过滤
- ✅ 多知识库隔离
- ✅ 批量向量生成
- ✅ 检索结果排序和去重
- ✅ 流式输出响应
- ✅ 多轮对话支持
- ✅ 工具调用(Function Calling)
- ✅ 附件上传和处理
- ✅ Token使用追踪
- ✅ 会话管理
- ✅ 插件化架构
- ✅ 工具注册和执行
- ✅ 关键词触发
- ✅ 优先级配置
- ✅ 工具配置管理
- ✅ 支持SQL执行、自定义动作等
项目结构
langchainModule/
├── main.py # FastAPI应用入口
├── config.py # 配置文件
├── start.py # 启动脚本
├── requirements.txt # 依赖列表
├── database/ # 数据库相关
│ ├── mysql_db.py # MySQL数据库连接和模型
│ └── vector_store.py # ChromaDB向量存储
├── routers/ # 路由模块
│ ├── chat.py # 聊天接口
│ ├── session.py # 会话管理
│ ├── knowledge_base.py # 知识库管理
│ └── recommended_question.py # 推荐问题
├── services/ # 服务层
│ ├── chat_model.py # 聊天模型服务
│ └── embedding_model.py # 向量模型服务
├── tools/ # 工具插件
│ ├── base.py # 工具基类
│ ├── registry.py # 工具注册中心
│ ├── register_info.py # 信息登记工具
│ └── pdf_report.py # PDF报告生成工具
├── utils/ # 工具函数
│ ├── document_loader.py # 文档加载
│ ├── document_processor.py # 文档处理
│ ├── text_splitter.py # 文本分块
│ ├── ocr.py # OCR识别
│ └── token_tracker.py # Token追踪
├── templates/ # HTML模板
│ ├── chat.html # 聊天页面
│ ├── knowledge_base.html # 知识库页面
│ └── ...
├── static/ # 静态资源
└── uploads/ # 上传文件目录
开发指南
添加新工具
参考 tools/README.md 文档,按照以下步骤添加新工具:
- 在
tools/目录创建工具类文件 - 继承
BaseTool基类 - 实现
execute方法 - 在
tools/registry.py中注册工具 - 系统会自动注册到数据库
自定义文档加载器
在 utils/document_loader.py 中添加新的文档类型支持:
- 实现文档加载函数
- 在
DOCUMENT_LOADERS字典中注册 - 返回
Document对象列表
配置说明
主要配置项在 config.py 中:
chunk_size: 文档分块大小(默认1000)chunk_overlap: 分块重叠大小(默认200)top_k: 检索返回的文档数量(默认3)kb_min_similarity: 知识库检索最小相似度(默认0.5)daily_token_limit: 每日Token限制(默认100万)
未来规划
- 待langchain1.0成熟后重构项目
注意事项
- 数据库配置:确保MySQL数据库已创建,并在
config.py中正确配置连接信息 - 向量库路径:ChromaDB数据存储在
chroma_data目录,请确保有写入权限 - API密钥:需要配置有效的AI模型API密钥,支持兼容OpenAI API格式的服务
- 文件上传:上传文件大小限制为50MB,可在配置中调整
- Token限制:系统会追踪Token使用量,超过每日限制会拒绝请求